Scalabilité et architectures distribuées avec SPIP

Suite aux échanges menés sur discuter.spip.net autour de la scalabilité horizontale de SPIP, plusieurs retours d’expérience et pistes techniques ont émergé. Cet article vise à les synthétiser afin de documenter les approches actuellement envisageables avec SPIP 4.
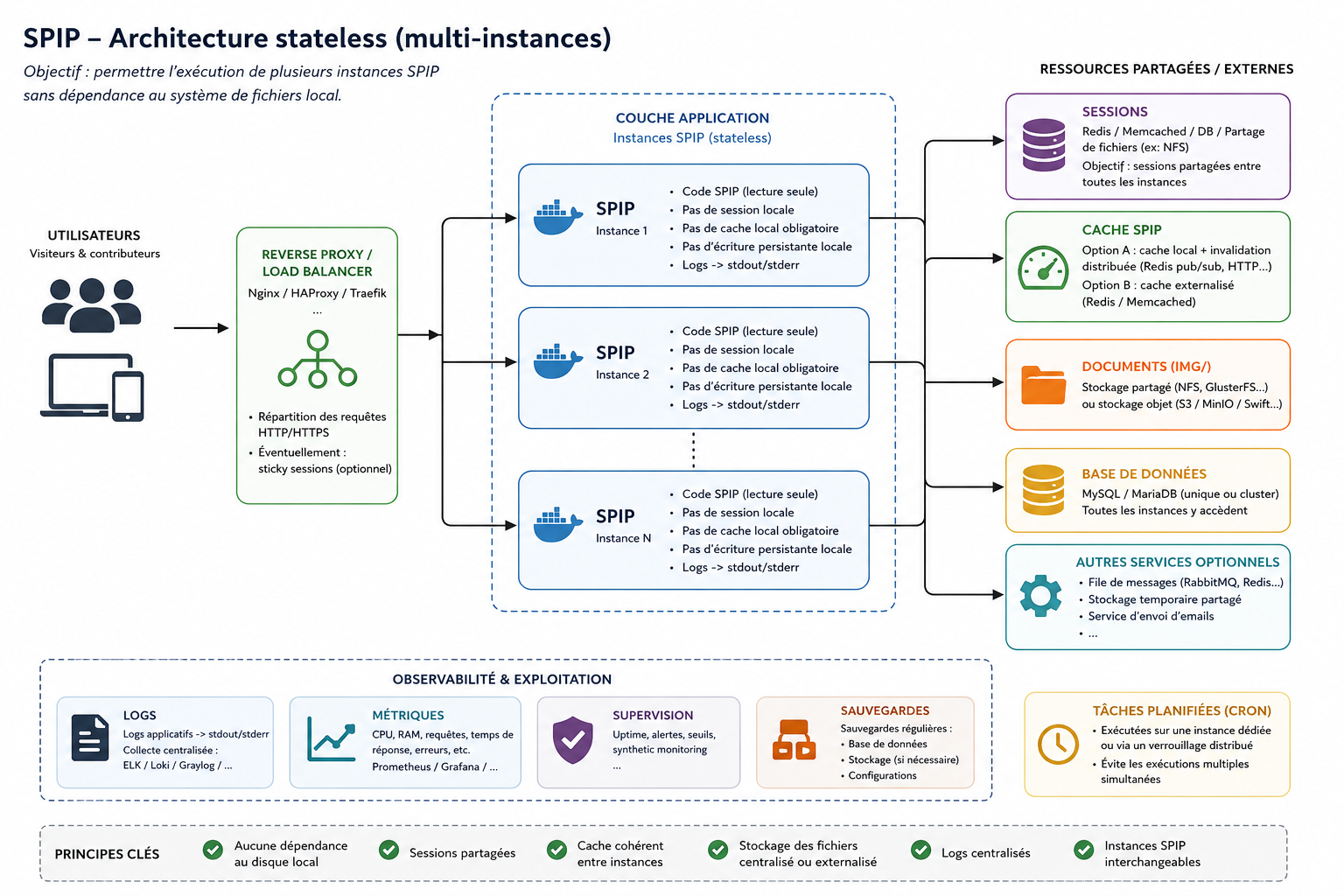
L’objectif n’est pas de transformer SPIP en framework « cloud native », ni de remettre en cause son fonctionnement historique, mais plutôt d’identifier les différents points de dépendance à une instance unique afin de rendre certaines architectures multi-instances plus réalistes et plus maintenables.
Rappel : qu’entend-on par « scalabilité horizontale » ?
La scalabilité horizontale consiste à faire fonctionner plusieurs instances d’une même application simultanément, derrière un répartiteur de charge (load balancer).
Dans cette approche, les différentes instances doivent idéalement être interchangeables et limiter au maximum leurs dépendances au système de fichiers local.
Dans le cas de SPIP, plusieurs éléments historiques rendent cette approche plus complexe :
- les sessions stockées sur disque ;
- les caches fichiers ;
- le répertoire IMG/ ;
- certaines écritures dans tmp/ ;
- certains plugins supposant implicitement une instance unique.
Pour autant, plusieurs retours montrent qu’il est déjà possible d’aller assez loin avec des adaptations ciblées.
Les logs applicatifs
Historiquement, SPIP écrit ses logs dans tmp/log/ via spip_log().
Dans des environnements conteneurisés (Docker, Kubernetes, plateformes managées, etc.), les logs applicatifs sont généralement collectés directement depuis la sortie standard (stdout) et la sortie d’erreur (stderr) des conteneurs.
Le plugin logs_stderr a été développé dans ce contexte afin de rediriger les appels à spip_log() vers stderr, évitant ainsi une dépendance forte au système de fichiers local pour la journalisation.
Cette approche permet notamment :
- une centralisation simplifiée des logs ;
- une meilleure intégration avec les outils d’observabilité ;
- une réduction des écritures locales ;
- une meilleure compatibilité avec des architectures distribuées.
Ce type d’adaptation constitue une première brique vers des instances SPIP plus « stateless ».
Les sessions
La gestion des sessions est probablement l’un des premiers sujets rencontrés lors d’une mise en place multi-instances.
Historiquement, les sessions SPIP reposent sur des fichiers stockés dans tmp/sessions/. Dans une architecture avec plusieurs serveurs ou conteneurs, cela peut provoquer des pertes de session lorsqu’une personne est redirigée vers une autre instance.
Plusieurs stratégies existent.
Répertoire partagé
La solution historiquement la plus simple consiste à partager le répertoire des sessions entre toutes les instances :
- NFS ;
- volume partagé ;
- stockage réseau.
Cette approche a notamment été utilisée dans certaines architectures de load balancing bien avant l’arrivée des environnements conteneurisés.
Elle reste aujourd’hui une solution pragmatique et relativement simple à mettre en œuvre.
Configuration PHP
PHP permet également de modifier le stockage des sessions indépendamment de SPIP.
Exemples :
session.save_handler = files
session.save_path = /repertoire/partageOu avec Redis :
session.save_handler = redis
session.save_path = "tcp://redis:6379"Dans ce cas, l’application SPIP ne change pas nécessairement de comportement : c’est PHP qui prend en charge la persistance des sessions.
Sticky sessions
Une autre approche consiste à configurer le répartiteur de charge afin qu’une même personne soit toujours redirigée vers la même instance.
Cette solution simplifie fortement la gestion des sessions, mais réduit une partie des bénéfices d’une architecture réellement distribuée.
Le cache SPIP
Le cache SPIP repose historiquement sur des fichiers stockés localement dans tmp/cache/.
Dans une architecture multi-instances, plusieurs approches peuvent être envisagées.
Cache local sur chaque instance
Chaque instance conserve son propre cache local.
Cette approche est souvent acceptable lorsque :
- les caches sont facilement régénérables ;
- les performances de génération restent raisonnables ;
- les invalidations sont correctement propagées.
C’est probablement l’approche la plus simple dans un premier temps.
Invalidation distribuée
Le principal sujet devient alors l’invalidation des caches entre les différentes instances.
Plusieurs mécanismes pourraient être envisagés :
- appel HTTP entre instances ;
- file de messages ;
- publication d’événements via Redis ;
- système de purge centralisé.
Le sujet dépasse largement SPIP lui-même et rejoint les problématiques classiques des architectures distribuées.
Cache externalisé
Certains retours évoquent également l’utilisation possible de Redis ou Memcached pour externaliser une partie du cache.
Cette approche demanderait cependant un travail plus important afin d’adapter certains mécanismes historiques du cache SPIP, fortement orientés fichiers.
Le répertoire IMG/
Le stockage des documents constitue probablement le principal point structurant d’une architecture distribuée.
Par défaut, les fichiers sont stockés localement dans IMG/.
Dans une architecture avec plusieurs instances, plusieurs stratégies sont possibles.
Volume partagé
Le répertoire IMG/ est partagé entre toutes les instances.
Cette solution reste aujourd’hui l’une des plus simples à mettre en œuvre.
Stockage objet
Une autre approche consiste à externaliser les documents vers :
- S3 ;
- MinIO ;
- Swift ;
- autre stockage objet compatible.
Cette approche rapproche davantage SPIP des architectures modernes utilisées dans les environnements conteneurisés.
Elle nécessite cependant un travail d’intégration plus important sur la gestion des uploads, des URLs et des traitements associés.
Les tâches planifiées
Dans une architecture multi-instances, les tâches planifiées peuvent également poser problème.
Si plusieurs instances exécutent simultanément les mêmes traitements CRON, cela peut provoquer :
- des doublons ;
- des verrouillages ;
- des traitements concurrents.
Plusieurs approches sont envisageables :
- une instance dédiée aux tâches CRON ;
- un mécanisme de verrou distribué ;
- un pilotage externe via l’orchestrateur.
Les plugins
Plusieurs échanges ont également mis en évidence que la compatibilité avec des architectures distribuées dépend fortement des plugins utilisés.
Certains plugins :
- écrivent dans tmp/ ;
- génèrent des fichiers temporaires ;
- supposent implicitement une instance unique ;
- utilisent des caches locaux spécifiques.
Une réflexion pourrait être menée autour d’une documentation ou d’une grille de compatibilité indiquant :
- compatible multi-instances ;
- nécessite stockage partagé ;
- nécessite adaptation ;
- incompatible sans refonte.
Une approche progressive et pragmatique
Les différents retours convergent globalement vers le même constat :
SPIP n’a pas été conçu initialement pour des architectures distribuées modernes, mais il reste possible de lever progressivement certaines dépendances locales sans remettre en cause son fonctionnement historique.
Dans de nombreux cas, une architecture hybride constitue probablement le meilleur compromis :
- frontal public distribué ;
- espace privé plus centralisé ;
- stockage partagé ;
- observabilité renforcée.
Avant même de parler de forte scalabilité, ces adaptations permettent déjà :
- une meilleure résilience ;
- une simplification des déploiements ;
- une meilleure intégration dans des plateformes modernes ;
- une amélioration de l’exploitation et de l’observabilité.
Pistes d’amélioration et travaux futurs
Plusieurs sujets pourraient faire l’objet de travaux complémentaires dans l’écosystème SPIP :
- abstraction du stockage des sessions ;
- externalisation partielle du cache ;
- adaptation du stockage des documents ;
- propagation distribuée des invalidations ;
- amélioration de l’observabilité ;
- documentation des bonnes pratiques multi-instances.
Ces évolutions pourraient prendre la forme de plugins dédiés, chacun traitant un aspect spécifique, plutôt qu’une refonte globale du fonctionnement historique de SPIP.
L’objectif ne serait pas de rendre SPIP dépendant d’architectures complexes, mais de permettre à celles et ceux qui en ont besoin d’aller progressivement vers des environnements plus distribués.
Derniers commentaires
# Le 19 octobre 2024 à 13:09, par nico
En réponse à : MagicMirror², ma configuration personnalisée
# Le 25 septembre 2024 à 12:01, par Teddy Payet
En réponse à : Un Nouveau Chapitre : Mon Admission dans un MBA en Intelligence Artificielle et Data Innovation
# Le 25 septembre 2024 à 11:20, par vY
En réponse à : Un Nouveau Chapitre : Mon Admission dans un MBA en Intelligence Artificielle et Data Innovation
# Le 21 juin 2024 à 13:49, par Teddy Payet
En réponse à : Home Assistant : Routine le matin avant l’école
# Le 21 juin 2024 à 10:47, par Teddy Payet
En réponse à : Ma domotique open source
# Le 16 juin 2024 à 17:15, par Eric
En réponse à : Ma domotique open source